共享知識庫、SOP 知識擷取
在上週的系列文章中,我們聚焦於律師事務所的 AI 應用場景:從合約審閱助手到雙語翻譯引擎再到內容品質檢查,AI 已逐步融入律所的日常。
然而,當這家律所準備進一步擴大 AI 的使用範圍,甚至分享經驗到一家大型企業的法務部門時,一連串更深層的考驗浮現眼前。
週一早晨,律所的技術合夥人和企業法務長在會議中熱烈討論:「我們的機密合約文本能放心交給雲端 AI 模型嗎?」、「AI 給的建議沒有出處,我們該信任嗎?」、「很多法務流程仰賴資深同事的經驗,AI 又該怎麼學會這些隱性知識?」
以上這些問題正是法律業導入 AI 時普遍遇到的挑戰。我們將延續律師事務所的場景,並擴展視角到企業法務團隊,深入分析導入生成式 AI 系統時的三大難題,以及針對每個問題的解法與對策。
在法律產業,資料隱私是不可動搖的原則。無論是尚未公開的合約草案、訴訟策略文件,還是客戶的個資與商業機密,都不能有半點洩露風險。
然而傳統的雲端 LLM 服務(如呼叫 OpenAI 的 GPT API)需要將文本發送到第三方伺服器處理,這對律所和企業法務而言是一大隱憂。事實上,一項調查顯示,超過一半的受訪企業擔心將機密資料輸入生成式 AI 可能導致外洩。因此,如何在不違反資料保密政策的前提下享受 AI 技術,成了首要挑戰。
解決之道是在公司內部部署私有化的 LLM。也就是說,不再把資料送到雲端,而是將模型「帶回家」。例如,企業可以使用開源的大型語言模型(如 Gemma 或 Qwen 等)來訓練屬於自己的法律 AI,並透過 FastAPI 等工具架設內網的 API 服務供內部系統(如 Odoo)調用。
這樣一來,機敏資料只在公司防火牆內流通,大幅降低外洩風險。同時,因為模型在本地運行,組織可以對輸入/輸出進行嚴格控管,包括權限驗證、存取記錄以及輸出結果審查。
下圖展示了私有 LLM 系統在企業內網中的架構。律師或法務透過 Odoo 前端將資料送入內部的 FastAPI、vLLM LLM 服務。LLM 在本地調用企業向量知識庫檢索相關資訊,生成建議後再返回給使用者。整個過程均在公司內網環境中完成。
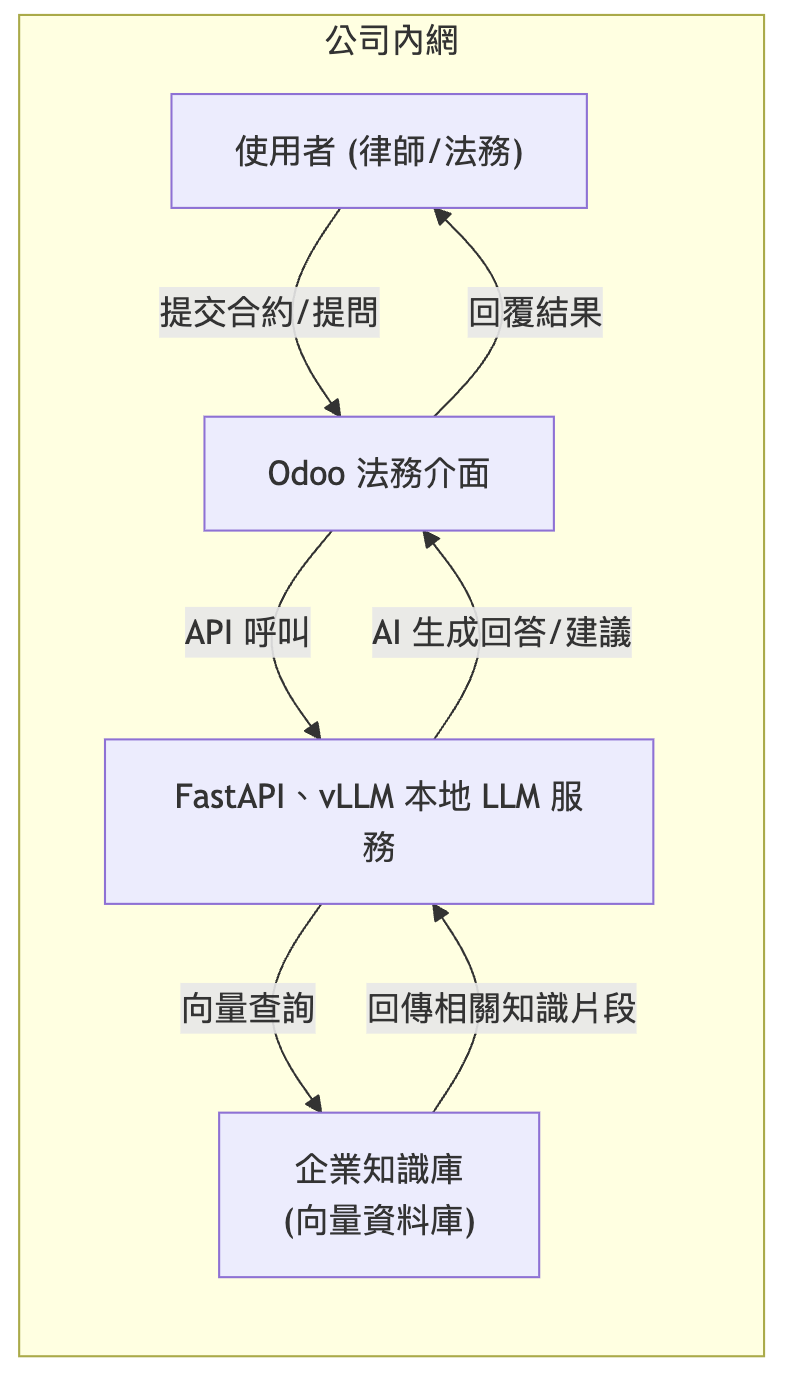
透過上述架構,律所與企業得以在離線隔離環境中運行 AI。值得一提的是,部署私有模型並不代表要放棄雲端的強大算力;許多現代開源模型已相對輕量,能在企業自有的伺服器甚至高階工作站上順暢運行。此外,本地部署也方便針對自有資料進行模型微調,進一步提升 AI 對法律語境的理解能力。
💡 Gary’s Pro Tip|資料安全部署
在導入法律 AI 時,資料安全必須零妥協。若預算允許,優先考慮「模型帶到資料所在處」,而非將資料送往模型所在的雲端服務。部署本地 LLM 時,記得關閉不必要的網路連接、定期更新,並對模型服務加上嚴格的存取控制。如此一來,即便是在離線環境,AI 系統也能堅守機密不外流,讓合規長與客戶都放心。
當然,本地部署也帶來新的課題,例如硬體資源需求、模型更新與維護成本等。但隨著 AI 硬體加速裝置價格逐漸親民,,私有模型部署正變得越來越可行且高效。在保障資料隱私的同時,也打下了 AI 成功落地的基礎。
即使採取了本地部署,有些極為敏感的資訊(如客戶姓名、身分證號、地址等)仍可在送入模型前先行脫辨識處理。我們可以利用 Python 簡單實現文字匿名化,將機密字串替換為標記,例如用 <NAME> 取代人名:
import re
doc = "客戶王小明的身份證號碼為 A123456789。"
# 將身分證字號替換為 <ID> 標記
doc = re.sub(r'[A-Z]\d{9}', '<ID>', doc)
# 將人名 "王小明" 替換為 <NAME>
doc = re.sub(r'王小明', '<NAME>', doc)
print(doc)
# 輸出: 客戶<NAME>的身份證號碼為 <ID>。
上例中,我們利用正則表達式將特定模式的敏感資訊過濾掉。對於法律文件而言,我們可事先建立敏感詞庫(如常見個資字段、公司機密代碼等),在將文字送入 LLM 前批量替換。經過這一道預處理,即使在內網環境中,我們也為資料多加了一道保險。
💡 Gary’s Pro Tip|實體萃取與匿名
在上面的例子,是很簡單的直接取代王小明這個名字,然而實務上,客戶的名字、地點等名詞實體,是不固定的,這時候就可以使用實體萃取(Entity Extraction)的模型,來做更精準、貼合實際場景的匿名化
另一項挑戰來自 AI 回答的可信度。法律從業人員對 AI 最大的顧慮之一是:「模型產生的結論有根有據嗎?」 傳統 LLM 在單獨使用時,經常會生成聽起來合理但實則虛構的內容,即所謂的幻覺 (hallucination)。例如,我們詢問 AI 某條款的依據時,它可能捏造一條不存在的法條來回答——對講究精確的法律工作而言,這樣的錯誤是不可接受的。
為了提升 AI 結果的可靠性與可解釋性,引入了檢索增強生成 (Retrieval-Augmented Generation, RAG) 技術。簡單來說,就是在模型回答問題時,即時檢索相關的知識或文件片段提供給模型參考,讓它「看著資料回答問題」。透過檢索企業內部經過驗證的知識庫內容,AI 的輸出不再憑空捏造,而是有章可循。對法律部門而言,這意味著模型的每句答案都可以對應到具體條文、案例或內部文件,大幅降低誤判風險。
實作 RAG 的關鍵步驟包括:建立內部向量索引,將法律文件、案例解析、合約範本等資料轉換為向量並存入資料庫;當使用者提出問題時,將問題也轉為向量並相似度檢索最相關的內容片段;最後將這些片段與問題一併餵給 LLM,讓模型在有依據的情況下生成回答。由於模型「看」到了可靠的參考資料,它較少憑空亂講,幻覺情形明顯改善。
以下是一段簡化的程式片段,示範如何計算問題與文件片段的向量相似度,以及如何在回答中加入可信度標示:
import numpy as np
# 假設 query_vec 是使用者問題的向量,doc_vec 是某段知識片段的向量
query_vec = np.array([0.1, 0.2, 0.7, 0.0])
doc_vec = np.array([0.1, 0.1, 0.6, 0.1])
# 計算 cosine 相似度
cos_sim = np.dot(query_vec, doc_vec) / (np.linalg.norm(query_vec)*np.linalg.norm(doc_vec))
print(f"相似度: {cos_sim:.2f}") # 輸出相似度,例如 0.95 (越接近1越相似)
# 模擬 AI 生成回答並附加可信度標示
answer = "根據合約第5條,買方應於交貨後30日內付款。"
confidence = 0.95 # 例如我們根據檢索結果計算出95%的信心
tagged_answer = f"{answer} (可信度: {confidence:.0%})"
print(tagged_answer)
# 輸出: 根據合約第5條,買方應於交貨後30日內付款。 (可信度: 95%)
上例首先計算了問題向量與文件向量的Cosine 相似度,模擬我們透過向量資料庫找到了一段高度相關的內容(相似度達 0.95)。接著,AI 的回答被附加了「可信度: 95%」的標示。實際情況中,我們可以根據檢索片段的相似度分數、數量以及交叉比對結果,來估計模型回答的可信度,並以透明的方式呈現給使用者。這種做法讓律師和法務可以快速判斷 AI 答案的可靠程度,必要時追溯引用的資料來源。
💡 Gary’s Pro Tip|答案有據可查
在法律情境下,千萬不要讓 AI 隨口猜測答案。強制要求 AI 引用來源是提升可信度的有效手段。不妨建立一個習慣:AI 每給出一項法律建議,都應附帶相關法規或檔案的引用編號,必要時可點擊查看原文。這不僅讓使用者安心,也方便日後審核追蹤。當 AI 的回答出現模稜兩可時,人類專業人員務必介入查證,切忌完全照單全收。讓 AI 成為可靠的助手,而非單獨做決定的仲裁者。
通過 RAG,我們有效降低了幻覺帶來的風險。但仍需注意,RAG 不是靈丹妙藥:模型仍有機率產生不相關的內容,或引入檢索資料中的錯誤。因此最佳實踐是在重要決策前保持人機協作——AI 提供初步結果,人類負責最終確認,確保萬無一失。
最後一項挑戰來自隱性知識的取得與運用。許多法律工作流程(SOP)並沒有完整寫在文件裡,而是深藏在資深法務人員的經驗之中。例如,一份契約審閱該按照哪些步驟、遇到某些特殊情況時該如何判斷,都可能只有個別員工心裡有數。當我們導入 AI,希望它協助自動化這些流程時,卻發現能提供給模型學習的結構化知識嚴重不足。這種知識孤島現象讓 AI 再聰明也無用武之地。
對策之一,是建立組織內的共享知識庫,將分散各處的顯性與隱性知識收集起來、結構化存儲。對律師事務所或企業法務部門而言,共享知識庫的內容可以包括:歷年合約範本條款及修改記錄、各類法律文件範例、內部FAQ問答彙整、法律專有名詞的Glossary 術語表、常用的條款模板、以及標準作業流程文件等。
透過現代化的知識管理工具,將上述資料數位化並分類標註,AI 便有了豐富的「素材庫」可以檢索和學習。例如,在前述 RAG 系統中,我們可以把這些知識庫資料嵌入向量資料庫,使 AI 能檢索到專業術語定義或過往範例來增強回答。
然而,僅有靜態知識還不夠,我們還需要將流程性的隱性知識外顯化。一個有效的方法是把隱性的 SOP 轉換為 Decision Tree(決策樹)或流程圖。
舉例來說,合約審閱流程可以拆解為:檢查基本資訊 → 條款合法性審核 → 利益衝突檢測 → 風險條款提示 → 輸出審閱報告 等步驟。我們可以繪製出這樣的決策樹,明確每一步的條件與結果。接著,利用 OpenAI 的Function Calling或其他代理工具,讓 AI 在需要時呼叫對應的函式來執行某個子步驟。
例如,當 AI 檢測到合約中有仲裁條款時,可以觸發一個 find_arbitration_clause() 函式去比對標準條文庫,確認該條款是否異常。如此一來,AI 不再是胡亂生成答案,而是按既定邏輯一步步完成任務。
值得一提的是,我們在設計提示詞時也能融入Workflow Prompt Template的概念。也就是為常見任務建立固定的提示模板,包含步驟說明和格式約定。例如設計一個「合約風險審查」的提示模板:
你是一位法律合約審查助手。請按照以下步驟審查合約:
1. 檢查合約基本資訊完整性(當事人、日期等)。
2. 檢查關鍵條款是否合法及合理。
3. 找出潛在利益衝突或不利條款。
4. 提出修正建議並引用相關法規依據。
輸出格式需包含:
- 風險項目清單
- 每項風險的說明與依據
- 建議的調整措施
像上面這樣的模板提供了一個明確的框架,讓 AI 按圖索驥地完成複雜任務。同時搭配術語表與自訂詞庫,確保 AI 使用統一的專業用語(例如將 "不可抗力" 固定使用而非其他說法)。實務上,有結構的提示詞和知識支援,能大幅提升 AI 在法律領域回答的一致性與專業度。
💡 Gary’s Pro Tip|打造法務知識共享文化
技術的效益離不開文化的配合。 在推行 AI 知識庫時,鼓勵團隊養成知識沉澱的習慣:每完成一項獨特的法律專案,就將經驗教訓和範本文件上傳至知識庫;定期舉辦內部分享會,邀請資深律師講解 SOP,同時錄製下來製作逐步指南。只有團隊願意持續充實知識庫,AI 才有源源不絕的新養分可用。換句話說,AI 再強大,也需要人類不斷「餵養」正確的知識,兩者相輔相成才能真正發揮價值。
透過上述對策,我們將隱性的經驗智慧轉化為 AI 可學習的形式,讓法律 AI 系統不僅懂法條,還能逐漸掌握「老鳥」們的實戰經驗。例如,某些合約條文表面合法但暗藏商業風險,這類經驗法則若寫入 SOP 規則並交付 AI,日後審約時模型便能自動提示。最終,律所與企業法務部門可藉由技術與知識管理並行,實現新人也能在 AI 輔助下做出資深水準的決策,整體提升團隊作業效率與質量。
站在法律科技轉型的路口,導入 AI 帶來的挑戰絕不僅僅是技術問題,更多的是對安全與信任的考驗。我們討論了資料隱私的顧慮、AI 結果可信度的問題,以及內部知識萃取的難題。所幸,每個挑戰都有相應的解方:通過私有模型部署來守護資料安全,以 RAG 架構增強 AI 的可靠度,並透過知識庫和流程圖讓隱性經驗得以傳承。
對律師事務所和企業法務而言,擁抱 AI 並非要取代人,而是為團隊添加一位強力助手。這位助手不會遺忘知識、不知疲倦,24/7 隨時待命處理繁瑣工作;但同時,我們也要為它打造良好的環境與培訓,使其遵守保密規則、說話有憑有據、並熟悉我們的辦事流程。只有人機優勢互補,才能真的做到事半功倍。
有了這一系列法律場景的分享,相信讀者可以舉一反三,為中小企業制定出一套可靠、安全的 Odoo x AI 導入策略。法律科技的未來已經在眼前,我們所要做的就是未雨綢繆,迎接挑戰並巧妙化解,讓 AI 真正成為推動企業數位自動化進步的引擎。


